サーチアルゴリズム
サーチとは
4日目までは、主にデータ構造をに関する説明をすすめてきました。ここからは、それらを用いたアルゴリズムについて解説していくことにします。すでに述べたとおり、アルゴリズムとはコンピュータが処理を行う「段取り」を意味します。
ここでは、そのうち、最も初歩的なアルゴリズムである、サーチ(search)アルゴリズムについて解説します。サーチとは文字通り、「探す」という意味で、特定のデータ構造の中から、必要なデータを「探す」処理のことを意味します。
サーチには、大きく分けて、リニアサーチと、バイナリサーチがあります。
リニアサーチ
まずは、一番簡単な、リニアサーチについて説明していきます。リニアサーチは、リストの先頭から終端に向かって目的の要素を探し出すアルゴリズムで、別名、線形探索とも言います。
アルゴリズムの手順
アルゴリズムの手順は極めて簡単で、以下のようになります。(図5-1.参照)
- リストの先頭から、要素を取り出す。
- 取り出した要素を、探したい要素と比較する
- 取り出したものが、探しているものと一致すれば、処理を終了する。
- 一致しない場合、次の要素に移行する。
- 次の要素がない(終端)だった場合、処理を終了する。(一致するものがない)
- 終端でなければ、2.に戻り、処理を継続する。
以上が、リニアサーチのアルゴリズムです。
図4-1.リニアサーチの構造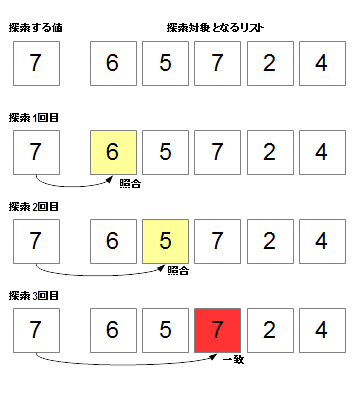
メリットとデメリット
このアルゴリズムのメリットは、実装が単純ということです。それにたしい、デメリットは、終了までのステップ数がリストの大きさに依存するため、保証されていない、という点にあります。
たとえば、1000個の要素のリストからデータを探す場合、最初に見つかれば、その場で終わりますが、目的のデータが最後にあった場合、1000回探索をすることになります。そのため、データ数が多い場合は向かない探索方法です。
バイナリサーチ
バイナリサーチとは
リニアサーチが、大量のデータでの探索に向かないのに比べ、同量のデータ量であっても、より短い時間でデータのサーチができるのが、バイナリサーチです。これは、第4日目で触れた、バイナリツリーを用いた探索方法です。
ただし、この方法が有効であるための条件は、あくまでも、要素が、昇順(もしくは降順)で、並べ替えられているということが必要です。では、実際、どのようなアルゴリズムなのでしょうか。
アルゴリズムの手順
では実際に、アルゴリズムの手順を見てみましょう。アルゴリズムは、以下のようになります。
- 配列をソートする(ここでは昇順でソートしたと仮定する)
- 探索の範囲を、リスト前部に広げる
- 配列の中央にある要素をと、目的の要素を比較する
- 中央の要素が、目的の要素なら、探索終了
- 中央の要素が、目的の要素より大きければ、探索の範囲を、中央より後半の部分にする
- 中央の要素が、目的の要素より大きければ、探索の範囲を、中央より小さい部分にする
- 3.に戻る
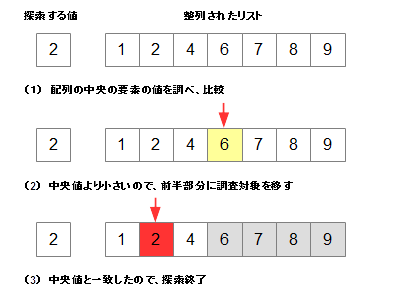
バイナリサーチのメリットとデメリット
このバイナリサーチのメリットは、すでに述べたように、なんといっても、探索の速さです。前述のリニアサーチの例のように、1000個のデータのなかから、目的の要素を探し出そうとすると、探索範囲が、1000 → 500 → 250 … → 4 → 2 → 1と変化していき、最悪でも11回の探索で目的のデータにたどり着くことができます。
これは、あくまでも「平均して」の話です。ただ、探索を何度か繰り返すようなプログラムの中では、同じデータでも、絶対にこの方法のほうが平均した時間は短くなるために、トータルとしての処理時間は短くなります。
では、この方法のデメリットはなんでしょうか?それは、この方法が、以下のようなデータに限られているという点です。
- 数値などのように、あらかじめ昇順、もしくは降順の順序をつけられるようなデータでなければならない。
- 探索の前に、あらかじめデータがソートされていなくてはならない
そのため、そういった条件を満たすようなデータでなければ使用できないという制約があります。
 |  |  |



